小红书星火&蒲公英参数解密
如下图:
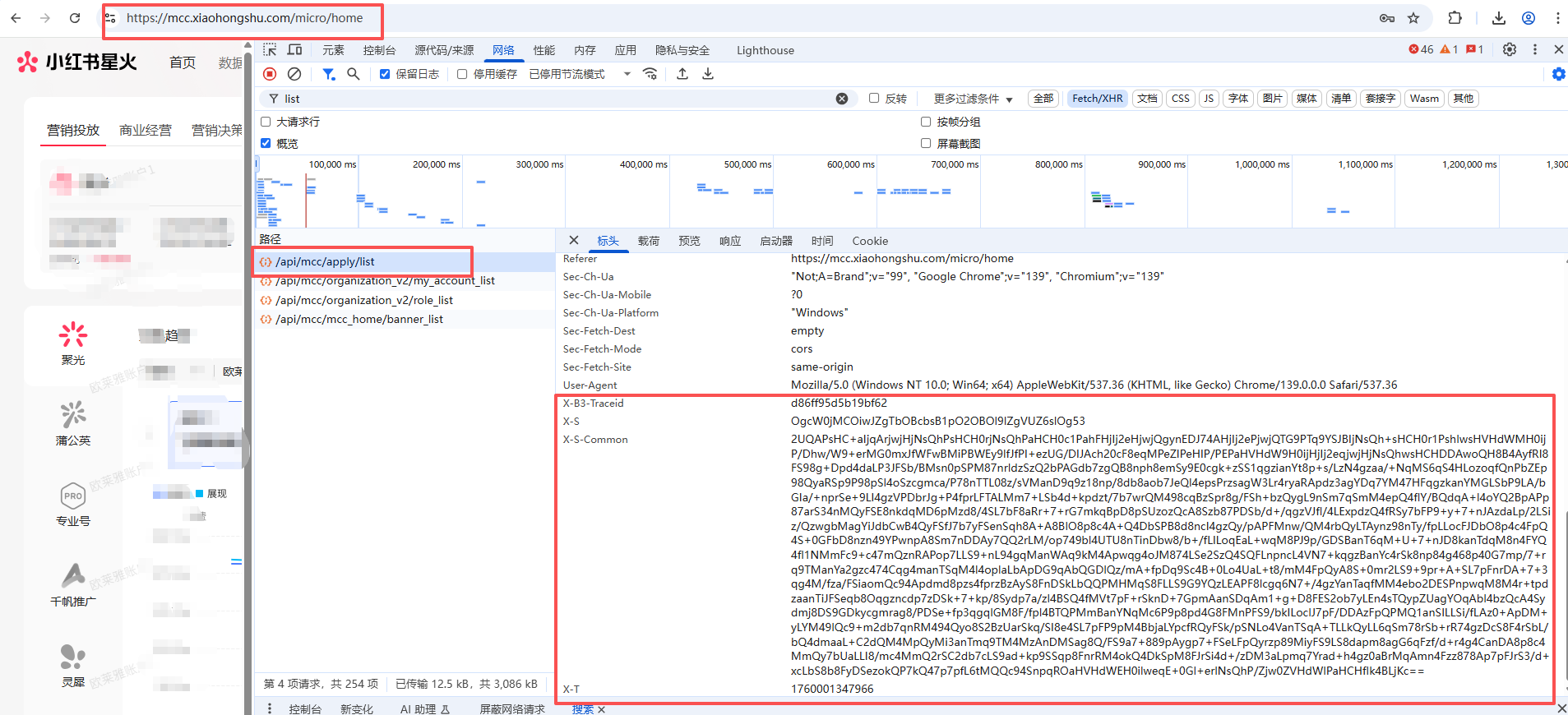
四个参数示意:
x-b3-traceid:随机16位字符串
x-s:参数+接口路径+时间戳的组合加密值
x-s-common:随机加密值
x-t:当前时间戳
小红书星火平台&蒲公英平台X-S、X-S-Common参数逆向转python代码后的结果如下:
import base64
import hashlib
import json
import random
def custom_base64_encode(input_str):
"""
完全模拟原JS代码的自定义Base64编码函数
"""
# 第一步:模拟JS中的UTF-8编码函数
def utf8_encode(s):
s = s.replace('\r\n', '\n')
result = []
for char in s:
code = ord(char)
if code < 128:
result.append(code)
elif code < 2048:
result.append((code >> 6) | 192)
result.append((code & 63) | 128)
else:
result.append((code >> 12) | 224)
result.append(((code >> 6) & 63) | 128)
result.append((code & 63) | 128)
return bytes(result)
# 第二步:模拟JS中的Base64编码函数
base64_chars = "A4NjFqYu5wPHsO0XTdDgMa2r1ZQocVte9UJBvk6/7=yRnhISGKblCWi+LpfE8xzm3"
# 执行UTF-8编码
data = utf8_encode(input_str)
data_len = len(data)
result = []
i = 0
while i < data_len:
# 处理第一个字节
byte1 = data[i]
i += 1
# 处理第二个字节(可能不存在)
byte2 = data[i] if i < data_len else None
if byte2 is not None:
i += 1
# 处理第三个字节(可能不存在)
byte3 = data[i] if i < data_len else None
if byte3 is not None:
i += 1
# 计算Base64索引
index1 = byte1 >> 2
if byte2 is None:
index2 = (byte1 & 3) << 4
index3 = 64 # 特殊标记,表示缺失
index4 = 64 # 特殊标记,表示缺失
else:
index2 = ((byte1 & 3) << 4) | (byte2 >> 4)
if byte3 is None:
index3 = ((byte2 & 15) << 2)
index4 = 64 # 特殊标记,表示缺失
else:
index3 = ((byte2 & 15) << 2) | (byte3 >> 6)
index4 = byte3 & 63
# 添加Base64字符
result.append(base64_chars[index1])
result.append(base64_chars[index2])
if index3 != 64:
result.append(base64_chars[index3])
if index4 != 64:
result.append(base64_chars[index4])
return ''.join(result)
def header_xs_common():
random_number = random.randint(-500000000, 500000000)
d = {"s0": 5, "s1": "", "x0": "1", "x1": "4.1.4", "x2": "Windows", "x3": "mcc-shell", "x4": "1.0.17",
"x5": "19897fff3c2se24gfzep1lwgob15g6e8ygzozr0tc50000354746", "x6": "", "x7": "",
"x8": "I38rHdgsjopgIvesdVwgIC+oIELmBZ5e3VwXLgFTIxS3bqwErFeexd0ekncAzMFYnqthIhJed9MDKutRI3KsYorWHPtGrbV0P9WfIi/eWc6eYqtyQApPI37ekmR6QL+5Ii6sdneeSfqYHqwl2qt5B0DBIx+PGDi/sVtkIxdsxuwr4qtiIhuaIE3e3LV0I3VTIC7e0utl2ADmsLveDSKsSPw5IEvsiVtJOqw8BuwfPpdeTFWOIx4TIiu6ZPwrPut5IvlaLbgs3qtxIxes1VwHIkumIkIyejgsY/WTge7eSqte/D7sDcpipedeYrDtIC6eDVw2IENsSqtlnlSuNjVtIvoekqt3cZ7sVo4gIESyIhE4+9DUIvzy4I8OIic7ZPwAIviX4o/sDLds6PwVIC7eSd7e0/k4IEveTZPMtVwUIids3s/sxZNeiVtbcUeeYVwvIvTGa05eSVwCgfosfPwoIxltIxZSouwOgVwpsr4heU/e6LveYPwfICNs1roeTFuMIiNeWL0sxdh5IiJsxPw9IhR9JPwJPutWIv3e1Vt1IiNs1qw5Ih/sYqtSGqwymqwDIvIkICptOjMS4n7sYPtVIiRzIh3sWPwKgIzrcnNsYUmuIihLqutzZPwEIv3eVPtk+pdeTzAsiMmLIiAsx7esTutycPwOIvoeSPwvIiJex0ImICdeS9NeSqt3Ixvs1Pw64B8qIkWyIvgsxFOekgveDS6edVtNIkF1I3Q6JuwCIkZ+I3KeWjSHarNekPwFIxh68qwZBfde1s0s1qtUqutdIkIaICSdoVtK+uwbIx7s0Wde1qwVnPtzIETgoutII3qCb/qcIiesW9OsiFveiqw2+PttIiWJI33sSVtYIEoeDpmTIvkDoWzKIvYrICoejPwLLPt2+qtUI3ruIhJsdA0e1qw9pSqRICG58ut2ZqtNIxhJIxTcIkbQIhNe3F3sVMMiHuwgICI6qVwQBVwTIh0eVMH/Iihvad/edPt7bVtmgWrNBgHVIkZI/VwoIk5s6IYLIkMNnPwhIkTnwqt+HVtKIhVVICk5ICQzZPwUIkZcICvsxPwWZZM7IvZcIvNs09KskVw+IvE7IhWh/crcICROc/MUICKedbvsDutKIhOsfPwtIEltI3veYqteI3RK",
"x9": random_number, "x10": 0, "x11": "lite"}
# 1. JSON序列化(等效stringify_default)
json_str = json.dumps(d, ensure_ascii=False, separators=(',', ':'))
# 2. UTF-8编码处理(等效encodeUtf8)
# 特别注意:处理\r\n转\n(与JS行为一致)
utf8_bytes = json_str.replace('\r\n', '\n').encode('utf-8')
# 自定义字母表(示例:将大小写字母互换)
custom_alphabet = b"ZmserbBoHQtNP+wOcza/LpngG8yJq42KWYj0DSfdikx3VT16IlUAFM97hECvuRX5"
# 创建转换表
original_alphabet = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
translation_table = bytes.maketrans(original_alphabet, custom_alphabet)
# 3. Base64编码(等效b64Encode)
base64_str = base64.b64encode(utf8_bytes).translate(translation_table).decode('ascii')
return base64_str
def header_xs(o, r, e, a, t):
"""
加密x-s
:param o: 时间戳,x-t的内容
:param r: test死值
:param e: 接口url 例:/api/cas/customer/web/model-ticket
:param a: 是否有json报文
:param t: json报文
:return: 加密结果
"""
# 构建输入字符串
parts = [
str(o),
str(r),
str(e),
json.dumps(t, ensure_ascii=False, separators=(',', ':')) if a else ""
]
input_str = "".join(parts)
# 计算MD5
md5_hash = hashlib.md5(input_str.encode('utf-8')).hexdigest()
# 使用自定义Base64编码
return custom_base64_encode(md5_hash) + "3"
# 使用示例
if __name__ == "__main__":
json_data = {"applyDataType":2,"pageIndex":1,"pageSize":20}
# 13位时间戳
o = "1760001347966"
# 固定数据
r = 'test'
# 接口地址
e = '/api/mcc/apply/list'
# 是否携带有json请求体参数
a = True
# 有的话传json,没有传None
t = json_data
result = header_xs(o, r, e, a, t)
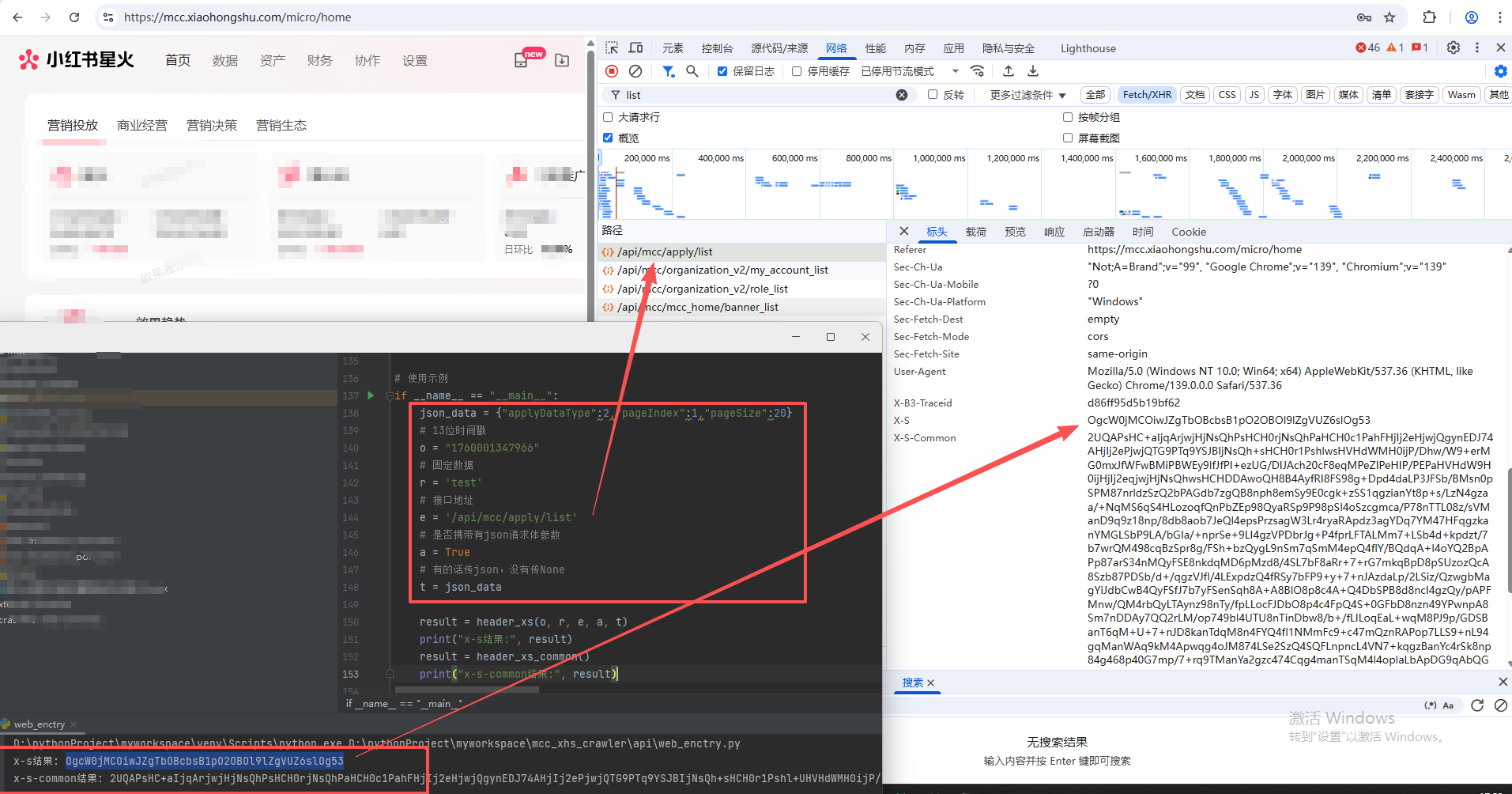
print("x-s结果:", result)
result = header_xs_common()
print("x-s-common结果:", result)
执行结果校验:
免责声明¶
本文为技术研究目的撰写,仅供学习交流。
- 内容时效性: 技术信息具有时效性,本文内容发布后可能已过时,请自行验证。
- 使用风险自担: 应用本文所述方法所产生的一切直接或间接后果,均由使用者自行承担。
- 合法合规使用: 严禁将本文内容用于任何违反法律法规或侵害他人权益的用途(如未经授权的爬虫、网络攻击、数据窃取等)。
- 版权声明: 本文为原创内容,转载需注明出处。文中引用的第三方资源,其版权归原作者所有。