抖音视频信息抓取
前几天,我接了个小项目,需要批量分析某音上的热门视频。我的第一反应当然是写个爬虫脚本,直接请求接口。然而,理想很丰满,现实很骨感——某音的反爬机制比我想象的还要严密,逆向的过程艰难无比,各种js加载器、循环跳转、动态生成的加密签名参数....
在当今的爬虫领域,对于像某音这样的大型App,获取数据的主流技术路径无非两条:
-
逆向分析派:深入剖析App或网页的JavaScript代码,还原核心加密参数(如a-Bogus、__ac_signature、msToken)的生成逻辑,直接在请求头中携带,实现高效抓取。
-
模拟浏览器派:通过工具直接控制一个真实的浏览器,所有的JS执行、参数生成、Cookie管理都由浏览器自动完成,程序只需“坐享其成”。
前者性能极高,是专业爬虫工程师的首选,但技术门槛高、维护成本大。而后者,以 Selenium 为代表,虽然速度稍慢,但其开发简单、绕过复杂加密、近乎于“无脑” 的优点,让它成为了快速原型、小规模数据抓取或个人开发者的绝佳选择。本文将详细讲解如何利用Selenium这条“捷径”,轻松抓取某音视频信息。
我们要抓取一个页面上的数据,首先要先找到给页面提供数据的接口
如下图,通过浏览器的开发者工具,在阅读完所有主要的网络请求后,我们发现其页面上的视频,图片,推文和博主信息都在一个名为 v1/web/aweme/detail的接口当中
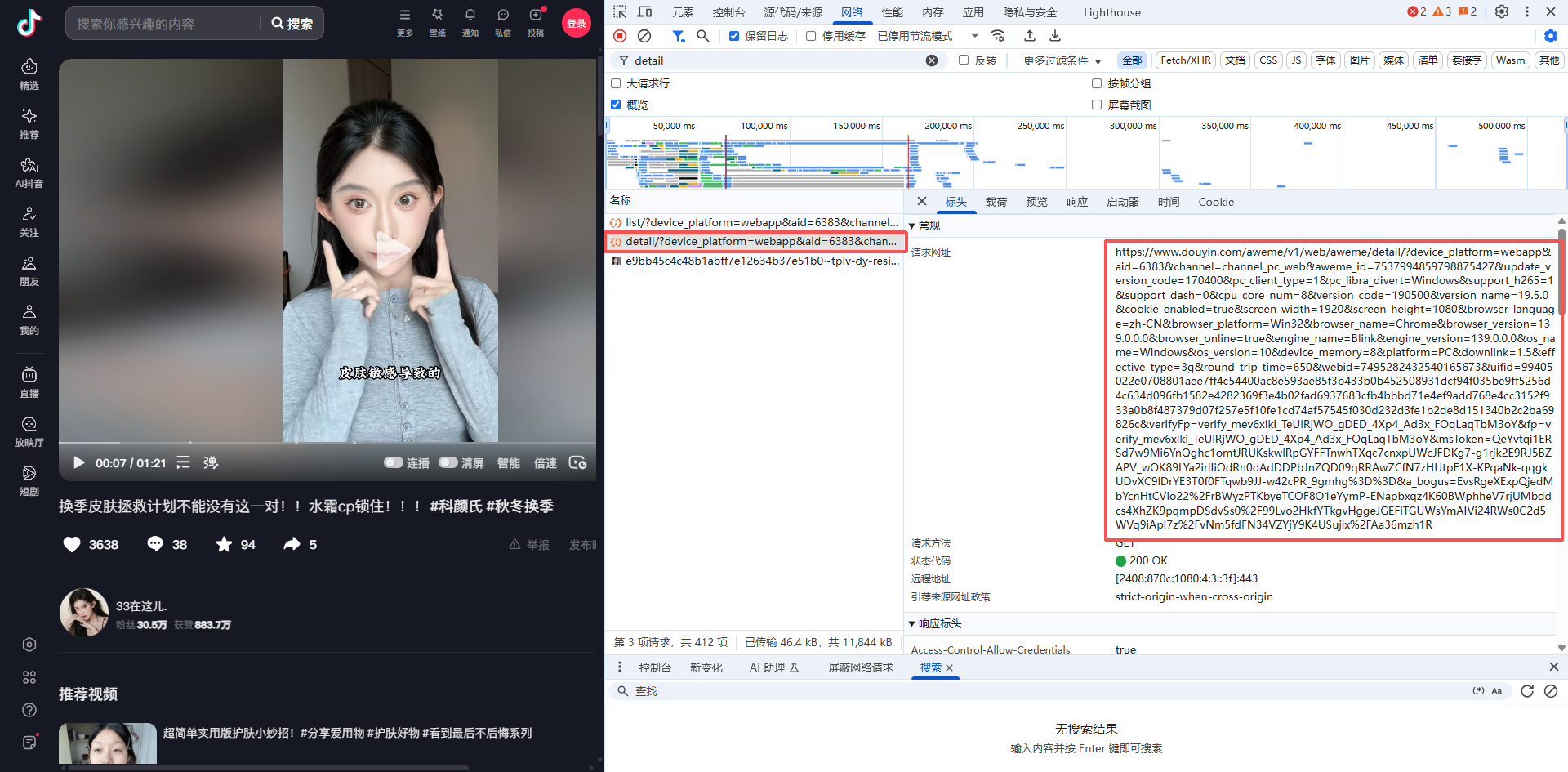
我们能清楚的看到,在这个接口的后面携带了各种校验参数,如果通过逆向的方法必定要花费大量的时间精力,而且每次接口参数的加密规则发生了变化,又得重新逆向补环境...
Selenium抓取的原理:
利用Selenium自动打开页面-->监听页面所有请求-->匹配到v1/web/aweme/detail接口-->获取到此接口的所有Heads、参数-->重放此次请求
实现代码如下:
import json
import time
import requests
from selenium.common import WebDriverException
from requests.adapters import HTTPAdapter
from seleniumwire import webdriver
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService, Service
def get_douyin_detail(url, cookies, referer, user_agent):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cookie': cookies,
'priority': 'u=1, i',
'referer': referer,
'sec-ch-ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': user_agent,
}
i = 0
while True:
try:
session = requests.session()
session.mount('http://', HTTPAdapter(max_retries=3))
session.mount('https://', HTTPAdapter(max_retries=3))
response = session.get(url, headers=headers)
response.encoding = 'utf-8'
return response.text
except Exception as e:
print('请求失败重试', e)
time.sleep(5)
i = i+1
finally:
session.close()
if i == 3:
return None
def web_home(url):
chrome_options = Options()
chrome_options.add_argument("--headless") # 无头模式
chrome_options.add_argument("--disable-gpu") # 禁用GPU加速
chrome_options.add_argument("--disable-infobars") # 禁用信息栏
chrome_options.add_argument("--disable-extensions") # 禁用扩展程序
chrome_options.add_argument("--disable-dev-shm-usage") # 禁用/dev/shm
chrome_options.add_argument("--log-level=3") # 提高日志级别
chrome_options.add_argument("--enable-unsafe-swiftshader")
chrome_options.add_argument('--no-sandbox') # 解决部分权限问题
chrome_options.add_argument('--ignore-certificate-errors') # 忽略证书错误的日志
chrome_options.add_argument("--user-data-dir=C:\\google_cache")
prefs = {"profile.managed_default_content_settings.images": 1} # 1 显示图片 2不显示
chrome_options.add_experimental_option("prefs", prefs)
try:
# 安装并获取 ChromeDriver 的路径,此处可能会失败,需要科学上网
driver_path = ChromeDriverManager().install()
# 创建 ChromeService 实例
chrome_service = ChromeService(driver_path)
# 打印 ChromeDriver 的路径
print("ChromeDriver Path:", driver_path)
driver = webdriver.Chrome(service=chrome_service, options=chrome_options)
except WebDriverException as e:
print('驱动过期!下载失败!')
return None, 601
with open('stealth.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
i = 0
driver.get('https://www.douyin.com/')
modal_id_start = url.find("modal_id=")
if modal_id_start >= 0:
video_id = url[modal_id_start + 9:modal_id_start + 19 + 9]
url = 'https://www.douyin.com/video/' + video_id
print(f"特殊链接重新构建:{url}")
while True:
if i == 3:
driver.close()
return None, 404
try:
driver.get(url)
break
except Exception as e:
print("抖音打开网页超时重试 Exception", e)
i += 1
print(f'打开成功->{url}')
# 休眠30s等待所有请求加载完成,此处根据机器和网络性能进行修改
time.sleep(30)
# 截取所有请求的 URL
detail_url = ''
headers = None
for request in driver.requests:
if 'v1/web/aweme/detail' in request.url:
detail_url = request.url
headers = request.headers
break
if detail_url == '' and headers is None:
print('视频链接打不开')
driver.close()
return None, 404
referer = headers.get('referer')
cookie = headers.get('cookie')
user_agent = headers.get('user-agent')
detail_txt = get_douyin_detail(detail_url, cookie, referer, user_agent)
print(detail_txt)
if detail_txt == '':
print('cookies已过期,或者出现反扒机制')
driver.close()
return None, 701
detail_json = json.loads(detail_txt)
if detail_json['aweme_detail'] is None:
print('视频链接打不开')
driver.close()
return None, 404
return detail_json, 200
if __name__ == '__main__':
print(web_home('https://v.douyin.com/iPcmYwqQ/'))
代码所需stealth.min.js资源地址:
执行结果如下:

json里面的内容,根据需要自行提取
免责声明¶
本文为技术研究目的撰写,仅供学习交流。
- 内容时效性: 技术信息具有时效性,本文内容发布后可能已过时,请自行验证。
- 使用风险自担: 应用本文所述方法所产生的一切直接或间接后果,均由使用者自行承担。
- 合法合规使用: 严禁将本文内容用于任何违反法律法规或侵害他人权益的用途(如未经授权的爬虫、网络攻击、数据窃取等)。
- 版权声明: 本文为原创内容,转载需注明出处。文中引用的第三方资源,其版权归原作者所有。