b站视频无水印下载
b站视频无水印下载python源码
可获取博主账号、昵称、主页链接、内容、发布时间、视频时长
因为b站的视频和声音是分开存储的,所以需要用到 moviepy 进行视频合成,对执行机器要有一定的要求,配置好的合成的速度更快
执行完后会在当执行的目录下生成一个bilibili_static的文件夹
文件夹内有一个音频.mp3文件、一个不带音频的.mp4文件、以及一个合成后的.mp4文件
执行结果如下图:
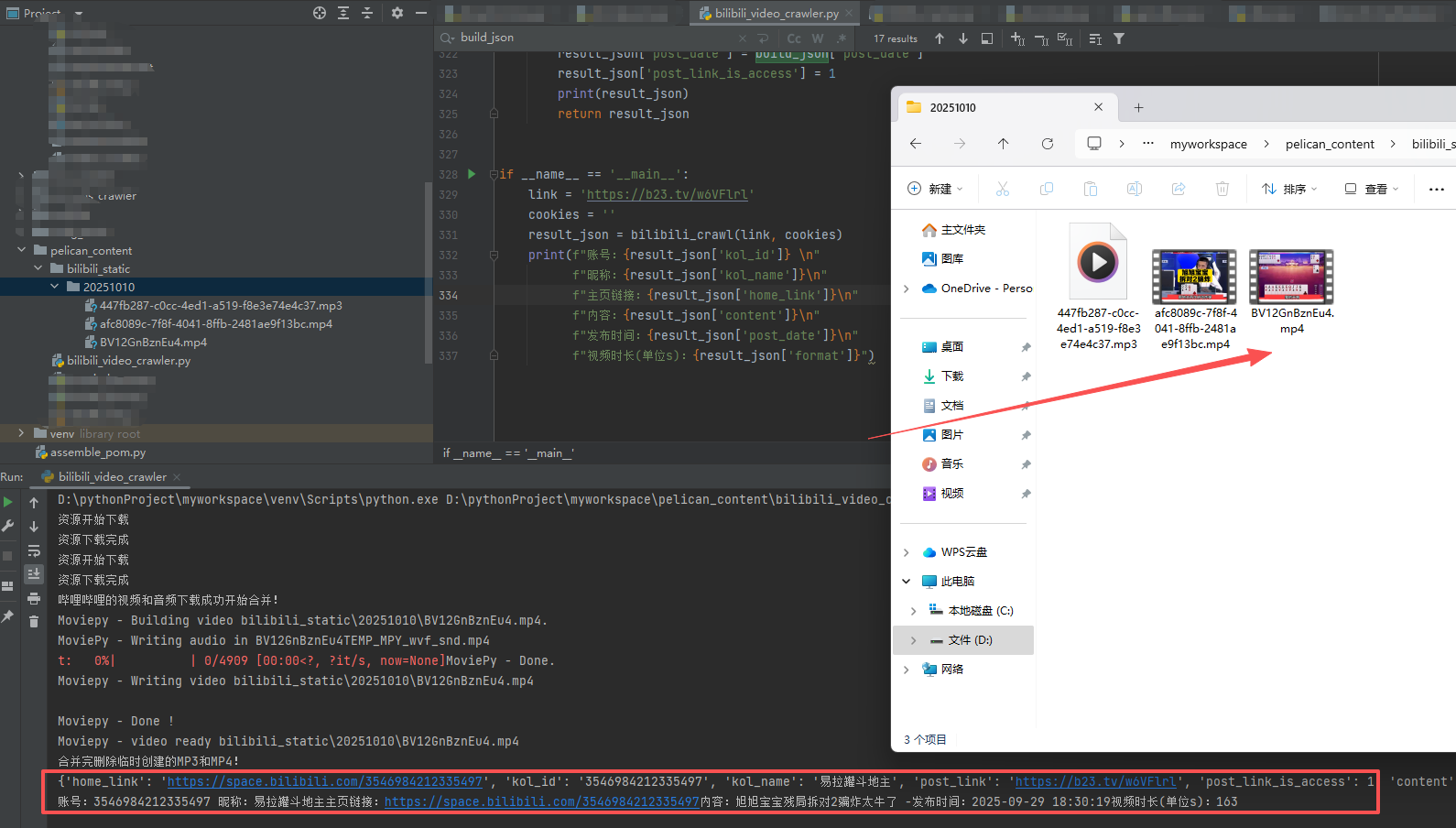
源码如下:
import datetime
import json
import re
import os.path
import time
import uuid
import os
from bs4 import BeautifulSoup
from moviepy.editor import VideoFileClip, AudioFileClip
import requests
from requests.adapters import HTTPAdapter
from datetime import datetime
def download(response, base_dir, file_name):
if not os.path.exists(base_dir):
os.makedirs(base_dir)
try:
print('资源开始下载')
with open(os.path.join(base_dir, file_name), 'wb') as f:
f.write(response.content)
print('资源下载完成')
return os.path.join(base_dir, file_name)
except Exception as e:
print('资源下载失败:', e)
return ''
def get_video_duration(file_path):
video = VideoFileClip(file_path)
duration = video.duration
video.close()
return int(duration)
def get_yyyymmdd():
now = datetime.now()
yyyymmdd = now.strftime("%Y%m%d")
return yyyymmdd
def request_web_home(url, cookie):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'cache-control': 'max-age=0',
'cookie': cookie,
'priority': 'u=0, i',
'sec-ch-ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
}
i = 0
while True:
i = i + 1
if i == 3:
return None
try:
session = requests.session()
session.mount('http://', HTTPAdapter(max_retries=3))
session.mount('https://', HTTPAdapter(max_retries=3))
response = session.get(url, headers=headers)
response.encoding = 'utf-8'
return response
except Exception as e:
print(f'请求失败,开始重试 {url}', e)
time.sleep(5)
continue
finally:
session.close()
def build_video_json(response):
soup = BeautifulSoup(response.text, 'html.parser')
if soup.text.startswith('{"code"') and json.loads(soup.text)['code'] == -404:
return None, 404
scripts = [script for script in soup.find_all('script') if
'window.__playinfo__' in script.text or 'window.__INITIAL_STATE__' in script.text]
# print(response.text)
play_info_json = None
state_info_json = None
for script in scripts:
if 'window.__playinfo__' in script.text:
play_info = re.findall(r'window.__playinfo__=(.*?)</', str(script).replace(' ', ''))
if play_info:
play_info_json = json.loads(play_info[0])
# print(json.dumps(play_info, ensure_ascii=False))
if 'window.__INITIAL_STATE__' in script.text:
STATE_info = re.findall(r'window.__INITIAL_STATE__=(.*?)};', str(script).replace(' ', ''))
if STATE_info:
state_info_json = json.loads(STATE_info[0] + "}")
# print(json.dumps(state_info_json, ensure_ascii=False))
video_url = ''
if play_info_json and play_info_json.get('data') and play_info_json.get('data').get('dash'):
for video in play_info_json['data']['dash']['video']:
if (video['id'] == 64 or video['id'] == 32) and 'avc1' in video['codecs']:
video_url = video['base_url']
break
# if video_url == '':
# return None, 701
mp3_url = ''
if play_info_json and play_info_json.get('data') and play_info_json.get('data').get('dash'):
for audio in play_info_json['data']['dash']['audio']:
if '40.2' in audio['codecs'] or video['id'] == 30280:
mp3_url = audio['base_url']
break
note_id = ''
kol_id = ''
kol_name = ''
home_link = ''
content = ''
post_date = ''
img_url_list = []
if state_info_json:
if state_info_json.get('bvid'):
note_id = state_info_json['bvid']
kol_id = state_info_json['upData']['mid']
kol_name = state_info_json['upData']['name']
home_link = 'https://space.bilibili.com/' + kol_id
if state_info_json.get('videoData'):
content = state_info_json['videoData']['title'] + ' ' + state_info_json['videoData']['desc']
# 发布时间
if state_info_json['videoData']['pubdate']:
# 转换为datetime对象
dt_object = datetime.fromtimestamp(state_info_json['videoData']['pubdate'])
# 格式化为字符串
post_date = dt_object.strftime('%Y-%m-%d %H:%M:%S')
if state_info_json.get('id'):
note_id = state_info_json['id']
for module in state_info_json['detail']['modules']:
if module['module_type'] == 'MODULE_TYPE_AUTHOR':
kol_id = module['module_author']['mid']
kol_name = module['module_author']['name']
home_link = 'https://space.bilibili.com/' + str(kol_id)
# 转换为datetime对象
dt_object = datetime.fromtimestamp(module['module_author']['pub_ts'])
# 格式化为字符串
post_date = dt_object.strftime('%Y-%m-%d %H:%M:%S')
if module['module_type'] == 'MODULE_TYPE_CONTENT':
for paragraph in module['module_content']['paragraphs']:
if paragraph['para_type'] == 1:
# 文字
try:
content += paragraph['text']['nodes'][0]['word']['words']
except Exception as e:
pass
if paragraph['para_type'] == 2:
# 图片
try:
img_url_list.append(paragraph['pic']['pics'][0]['url'])
except Exception as e:
pass
return {
'home_link': home_link,
'content': content,
'note_id': note_id,
'kol_id': kol_id,
'kol_name': kol_name,
'video_url': video_url,
'mp3_url': mp3_url,
'img_url_list': img_url_list,
'post_date': post_date
}, 200
def download_mp4(mp4_url, mp3_url, note_id, referer, cookie):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Referer': referer,
'cookie': cookie,
'priority': 'u=0, i',
'sec-ch-ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
}
i = 0
while True:
if i == 3:
return '下载失败'
i = i + 1
try:
session = requests.session()
session.mount('http://', HTTPAdapter(max_retries=3))
session.mount('https://', HTTPAdapter(max_retries=3))
mp3_response = session.get(
mp3_url,
headers=headers,
)
mp4_response = session.get(
mp4_url,
headers=headers,
)
if len(mp3_response.content) < 10 or len(mp4_response.content) < 10 or \
mp3_response.text.replace(' ', '').find('429TooManyRequests') > 0 or mp4_response.text.replace(' ', '')\
.find('429 Too Many Requests') > 0 or mp3_response.status_code == 429 or mp4_response.status_code == 429:
time.sleep(5)
continue
mp3_file_path = download(mp3_response, os.path.join('bilibili_static', get_yyyymmdd()),
f'{str(uuid.uuid4())}.mp3')
mp4_file_path = download(mp4_response, os.path.join('bilibili_static', get_yyyymmdd()),
f'{str(uuid.uuid4())}.mp4')
print("哔哩哔哩的视频和音频下载成功开始合并!")
# 加载视频和音频文件
video = VideoFileClip(mp4_file_path)
audio = AudioFileClip(mp3_file_path)
# 将音频合并到视频中
final_video = video.set_audio(audio)
# 保存输出文件
file_path = os.path.join('bilibili_static', get_yyyymmdd(), f'{note_id}.mp4')
final_video.write_videofile(os.path.join('bilibili_static', get_yyyymmdd(), f'{note_id}.mp4'),
codec="libx264", audio_codec="aac")
print("合并完删除临时创建的MP3和MP4!")
# os.remove(mp4_file_path)
# os.remove(mp3_file_path)
return file_path
except Exception as e:
print(f'哔哩哔哩下载资源失败', e)
finally:
session.close()
time.sleep(5)
continue
def download_img(url, note_id, referer):
headers = {
'Referer': referer,
'sec-ch-ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36',
}
i = 0
while True:
if i == 3:
return '下载失败'
i = i + 1
try:
session = requests.session()
session.mount('http://', HTTPAdapter(max_retries=3))
session.mount('https://', HTTPAdapter(max_retries=3))
response = session.get(
url,
headers=headers,
)
if len(response.content) < 10 or response.text.replace(' ', '').find('429TooManyRequests') > 0 or \
response.status_code == 429:
time.sleep(5)
continue
file_path = download(response, os.path.join('bilibili_static', get_yyyymmdd()), f'{note_id}.jpg')
return file_path
except Exception as e:
print(f'请求失败{url}', e)
finally:
session.close()
time.sleep(5)
continue
def bilibili_crawl(link, cookies):
result_json = {
'home_link': '',
'kol_id': '',
'kol_name': '',
'post_link': link,
'post_link_is_access': 0,
'content': '',
'video_url': '',
'image_path_list': [],
'post_date': ''
}
resp = request_web_home(link, cookies)
build_json, status = build_video_json(resp)
if status == 404:
# 打不开页面
print(f'{link}打不开页面')
return result_json
if status == 701:
# 打不开页面
print(f'bilibili cookies已经过期')
return result_json
if status == 200:
mate_url = f'https://www.bilibili.com/video/{build_json["note_id"]}'
if build_json["note_id"].startswith('cv'):
mate_url = f'https://www.bilibili.com/read/{build_json["note_id"]}'
format = ''
if build_json['video_url'] != '':
# 下载视频
result_json['video_url'] = download_mp4(build_json['video_url'], build_json['mp3_url'], build_json['note_id']
, mate_url, cookies)
if result_json['video_url'] == '下载失败':
print(f'下载失败bilibili {link}重新塞回队列')
result_json['reverse'] = 1
return result_json
else:
format = get_video_duration(result_json['video_url'])
image_path_list = []
if build_json['img_url_list'] and len(build_json['img_url_list']) > 0:
for i, img_url in enumerate(build_json['img_url_list']):
url_path = download_img(img_url, build_json['note_id'] + '_' + str(i),
mate_url)
image_path_list.append(url_path)
result_json['format'] = format
result_json['image_path_list'] = image_path_list
result_json['home_link'] = build_json['home_link']
result_json['kol_id'] = build_json['kol_id']
result_json['kol_name'] = build_json['kol_name']
result_json['content'] = build_json['content']
result_json['post_date'] = build_json['post_date']
result_json['post_link_is_access'] = 1
print(result_json)
return result_json
if __name__ == '__main__':
link = 'https://b23.tv/w6VFlrl'
cookies = ''
result_json = bilibili_crawl(link, cookies)
print(f"账号:{result_json['kol_id']} \n"
f"昵称:{result_json['kol_name']}\n"
f"主页链接:{result_json['home_link']}\n"
f"内容:{result_json['content']}\n"
f"发布时间:{result_json['post_date']}\n"
f"视频时长(单位s):{result_json['format']}")
免责声明¶
本文为技术研究目的撰写,仅供学习交流。
- 内容时效性: 技术信息具有时效性,本文内容发布后可能已过时,请自行验证。
- 使用风险自担: 应用本文所述方法所产生的一切直接或间接后果,均由使用者自行承担。
- 合法合规使用: 严禁将本文内容用于任何违反法律法规或侵害他人权益的用途(如未经授权的爬虫、网络攻击、数据窃取等)。
- 版权声明: 本文为原创内容,转载需注明出处。文中引用的第三方资源,其版权归原作者所有。